Build a Web Scraping & Data Cleaning Pipeline with Python, BeautifulSoup, Pandas, and SQL. Automate messy data collection, cleaning, and structuring into dashboards — saving 80% of manual effort. Perfect for data science portfolios and recruiter visibility.
In real-world data science, raw data is messy. It often comes from multiple unstructured sources like websites, APIs, and CSVs. This project demonstrates how to:
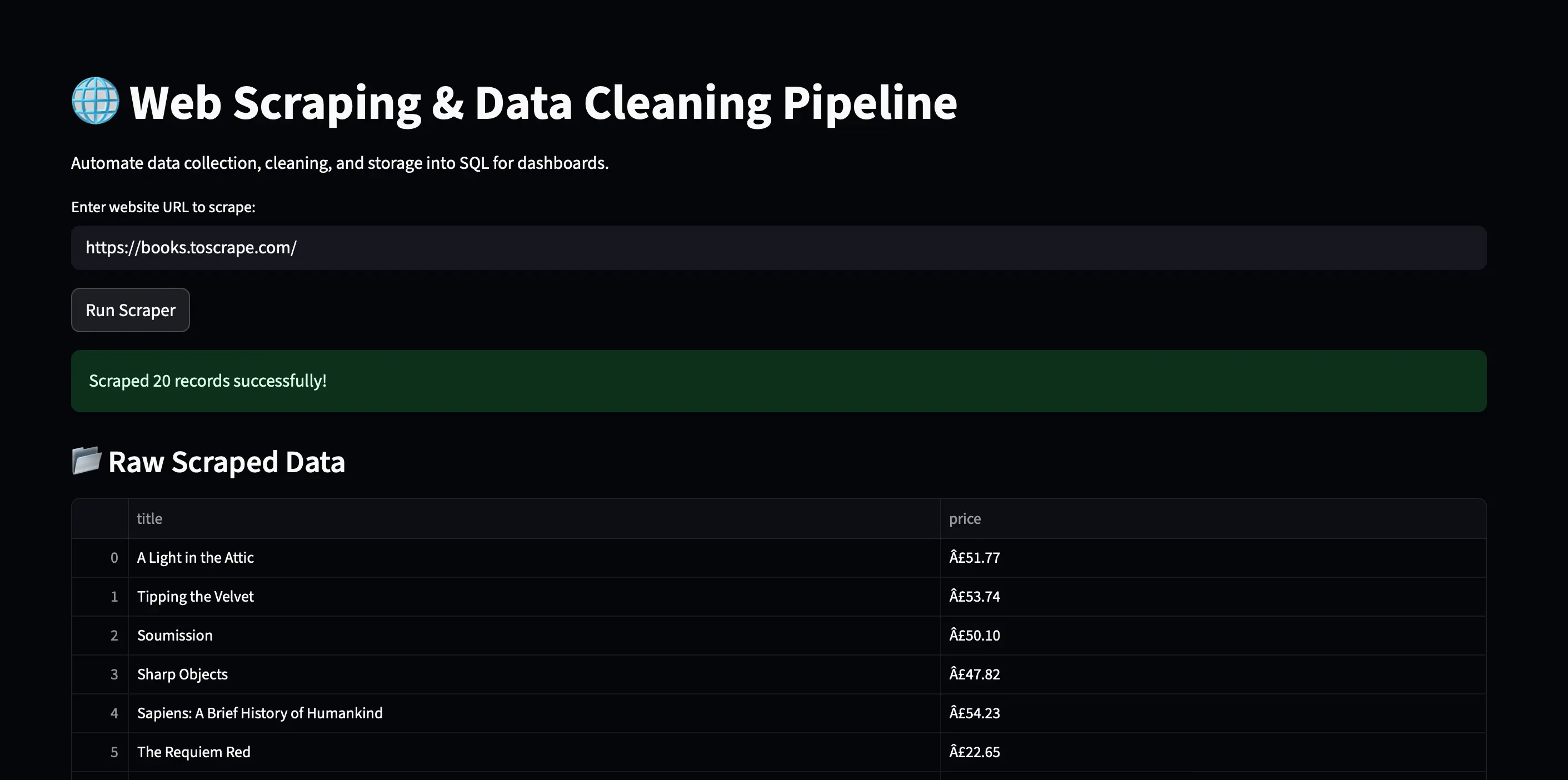
Scrape data from websites using BeautifulSoup
Clean & structure datasets with Pandas
Store processed data into an SQL database
Prepare clean data for analysis & dashboards
✅ Recruiter Signal: “This candidate can automate data collection, clean datasets, and deliver ready-to-analyze insights.”
🛠️ Tech Stack
Python – automation & scripting
BeautifulSoup – scraping web data
Pandas – data wrangling & cleaning
SQLite/MySQL – structured database storage
SQLAlchemy – database connection in Python
💡 Features
🌐 Automated web scraping from multiple pages
🧹 Data cleaning pipeline: handle missing values, duplicates, and formatting
📂 Save structured datasets into SQL for long-term use
📊 Dashboard-ready outputs in CSV/Excel/SQL
⚡ 80% faster than manual collection
📂 Project Structure
web_scraping_pipeline/
│── app.py # Main pipeline script
│── scraper.py # Web scraping functions
│── cleaner.py # Data cleaning functions
│── database.py # SQL storage logic
│── requirements.txt # Dependencies
│── README.md # Documentation
│── data/ # Raw + Cleaned data (sample CSVs)
🚀 How to Run Locally
Clone the repo:
git clone https://github.com/yourusername/web_scraping_pipeline.git
cd web_scraping_pipeline
Install dependencies:
pip install -r requirements.txt
Run the scraper:
python app.py
📝 Example Workflow
1. Scraping with BeautifulSoup
import requests
from bs4 import BeautifulSoup
url = "https://example.com/products"
html = requests.get(url).text
soup = BeautifulSoup(html, "html.parser")
products = []
for item in soup.find_all("div", class_="product"):
title = item.find("h2").text
price = item.find("span", class_="price").text
products.append({"title": title, "price": price})
Fits perfectly into real-world data analyst workflows
🌐 Recruiter-Friendly Signal
This project proves you can collect, clean, and organize messy web data into structured insights, saving time and enabling faster analysis — exactly what recruiters and hiring managers want.